
Thanks for the Memoize
Those of you who know me know I have an absolute crap memory. Anything short of Monty Python dialog and track listing from a 90s alt rock band and I am dead to rights. Fortunately for us, however, computers are far more competent when it comes to remember things.
The Concept
The technique we are looking at today is called memoization. Let’s start by discussing pure functions. The idea behind a pure function is that, no matter what input you give it, it is always going to give the same output. Now consider if you have a process intensive function or one that requires a lot of overhead. If you already know the result of running the function when provided a certain set of parameters why utilize your resources to run it again. Memoization allows us to store the result of a previous execution of a function using the parameters to that function as the key. The following code snippet demonstrates what a memoized function might look like:
The Execution
const memoize = {};
const getResult = async (n1, n2) => {
const key = `${n1}_${n2}`;
if (!memoize[key]) {
memoize[key] = await resourceIntensiveFunction(n1, n2);
}
return memoize[key];
};
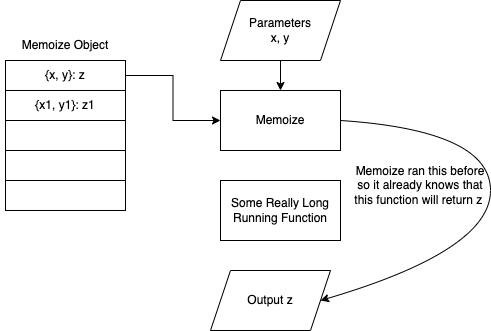
Let’s take a look at the code. We start with an object called memoize that will store our parameters and the results as a key value set. Next we have our function called getResult that takes two parameters: n1 and n2. For simplicity’s sake of this let’s assume that the order matters. We are going to create a variable key using the concatenation of the two parameters.
Now we need to check to see if the memoize object contains a value for that key. We check and, if it doesn’t, we have no choice but to run the resource intensive function. If we run the function we must also store the results in the memoization object for future execution. This way the next time run this function for these same parameters it’ll find the result in the object and skip the resource intensive function.
Memoize when query has been previously run
Memoize when query has not been previously run
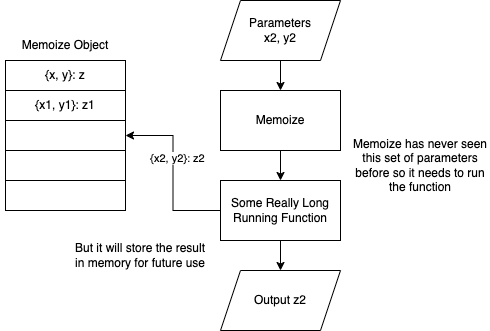
The Benefits
This can be useful in a number of scenarios. If, for instance, you have a long series of calculations that take an extensive amount of time and resource this good be a worthwhile optimization. It can also be valuable if you have something that requires high network throughput or a lot of temporary disk space. For any of these scenarios the advantage is two fold: It eliminates the need to run functions that have been previously executed and it frees up resources for those that need to be calculated because they aren’t competing for resources with those functions that are already mapped.
The Challenges
There are situations where this might not be the right approach so don’t always use this paradigm. If your function is not a pure function and it changes based on external factors then you don’t want to use this approach as it’ll always give you the values from the first run not taking into consideration those other variables. You also don’t want to use this if the application will rarely run the function with the same set of parameters. In that case you’ll have an increasingly large data structure that rarely gets used.
That’s pretty much it for memoization. It’s a pretty simple pattern with a very intimidating sounding name. There are a lot of applications for it and, hopefully, this gives you a better idea of what is happening under the hood. Now, if you’ll excuse me, I have to go remember what it was I was going to do this evening.
Source code available on GitHub